Den Quellcode kann man schnell anpassen und auch auf den Systemen aktualisieren. Eine Änderung am Datenbankdesign ist meist nur schwer zu machen. Oft auch nicht ganz leicht für den Kunden, der eine Webapplikation von einem Freelancer erworben hat, durch zuführen. Mag sein, dass hier der eine oder andere eine gute Geschäftsphilosophie sieht, die dauerhaft Geld bringt, dennoch gibt es auch andere die die Qualität der Software ansich mehr schätzt und durch zufriedene Kunden mit wenig Support-Aufwand sich einen Namen macht.
Wie man Änderungen am Datenbank-Design update sicherer machen kann und auch Aktualisierungen störungsfrei gestalten könnte, bei der eine oder gar mehrer Datenbank-Anpassungen vorgenommen wurden, habe ich in einem anderen Post beschrieben. Hier geht es darum, dass man Tabellen und die dazugehörigen Datensätz mit dem Programmieren anlegen, bzw nutzt, ohne gezielt nochmal eine Tabelle in der Datenbank anzulegen.
Diese hier vorgetragenen Lösungen sind zum Teil durch existierende Frameworks bereits abgedeckt, doch hier geht es um Effizienz und zwar im Betrieb der Software. Da ist es manchmal besser bestimmte Operationen selber zu erstellen und damit den grossen Overhead und viele nicht genutzte Funktionen zu vermeiden.
Einfaches Programmieren und effizientes Programmcode-Design soll die Software für ewig lauffähig halten.
Manche erinnern sich sicherlich noch an die Anfänge von PHP und die dauernden Umstellungen am Klassensystem und anderem, welches es notwendig machte unzählige Zeilen Code nochmal durch zu arbeiten und teils alles neu aufzusetzen. Objektorientierter Ansatz ist gut, doch muss man immer das Verhältnis waren und oft sind Objekte für einige Lösungen überdimensioniert.
Idee
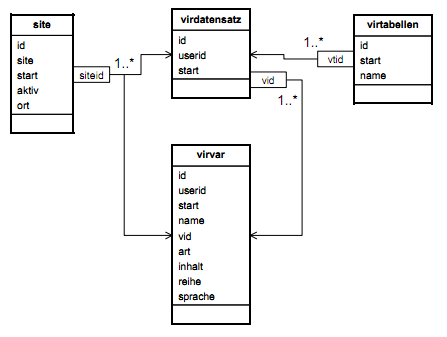
Benötigte Datenbank Felder und Tabellen werden während des Programmierens einfach eingesetzt und entsprechend zur Laufzeit angelegt. Die virtuellen Tabellen, werden in in einer Tabelle gespeichert, deren Felder werden ebenso in einer Tabelle gespeichert. Die Daten zu den Felder werden in einer gesonderten Tabelle gespeichert. Damit entfallen zukünftige Datenbank-Anpassungen für einfache Tabellen, da diese erst auf Zuruf angelegt werden und diese gekapselt per Code. Oft werden Tabellen nur als einfacher Datenspeicher, ohne spätere komplexe Auswertungen, genutzt. Genau da ist der Nutzen der virtuellen Tabellen angesiedelt.
Vorgehen
Wir erstellen 3 Tabellen und die notwendigen Funktionen, um diese später für den Zugriff zu nutzen.
Das Erstellen dieser 3 Tabellen kann mittels des zuvor schon beschrieben Verfahren (älterer Blogpost) eingebunden und somit merkt der Betreiber nicht mal die Erweiterung ansich.
Umsetzung
Benötigte Tabellen
- virdatensatz (id, start, name)
- virtabellen (id, userid, start)
- virvar (id, userid, start, name, vid, art, inhalt, reihe, sprache)
Funktionsübersicht der virtuellen Tabellen
| Funktionsname | Parameter | Erklärung |
|---|
| virtabelle_anlegen | name | Legt eine virtuelle Tabelle an |
| virtabelle_holen | tabelle, anlegen=0 | Liefert die Referenz auf eine Tabelle |
| virdatensatz_anlegen | tabelle, userid, tabelleanlegen=1 | Legt einen Datensatz in einer
virtuellen Tabelle an. Legt diese
ggf. an |
| virdatensatz_holen | tabelle, feld=““, datenid=0, counted=0,
sql_option=““, wherefelder=array(),
limit_start=0, limit_ende=0 | Liefert die Datensätze einer
virtuellen Tabelle |
| virdatensatz_komplett_aendern | tabelle, userid, virdatensatzid, werte | Ändert einen kompletten Daten-
satz mit den übergebenen Werten als Attribute |
| virdatensatz_komplett_anlegen | tabelle, userid, werte, tabellenanlegen=1 | Legt einen Datensatz komplett
mit Attribute an und erstellt ggf.
die virtuelle Tabelle |
| virdatensatz_loeschen | tabelle, catid | Löscht einen virtuellen Datensatz |
| virvar_register | var, tabelle, id, userid, wert=””, sprache=0 | Legt eine dynamische Variable
zu einem dynamischen Datensatz |
| virvar_unregister | var, tabelle, id, readonly=0,
nur_ausgeben=0, sprache=0 | Liefert eine dynamische Variable
von einem dynamischen Datensatz |
Anmerkung: Bei Parameter mit einer Wertzuweisung handelt es sich um optionale Parameter mit
einem Standardwert
Funktionen
function virtabelle_anlegen ($name) {// legt eine virtuelle Tabelle an.
$tname = addslashes(trim($name));
if ($tname == "")
return -1;
$sql = "insert into virtabellen (start, name) values (".time().", '".$tname."')";
return virtabelle_holen($name);
}
function virtabelle_holen ($tabelle, $anlegen=0) {
// prüft ob eine virtuelle tabelle existiert
// bei anlegen = 1, wird diese Tabelle ggf angelegt
// gibt die ID zurueck von tabelle eine Zahl ist
$tabelle = trim($tabelle);
if (intval($tabelle) > 0)
return $tabelle;
if ($tabelle == "")
return -1;
global $System;
$id = intval($System[virtabellen][$tabelle]);
if ($id < 1):
$sql = "select id from virtabellen where name = '".addslashes($tabelle)."'";
list($id) = datensatz_holen($sql);// macht mysql_query und dann mysql_fetch_array
endif;
if ($id > 0):
$System[virtabellen][$tabelle] = $id; // zwischenspeichern, um performance zu gewinnen
return $id;
endif;
if ($anlegen == 1)
return virtabelle_anlegen($tabelle);
return 0;
}
function virdatensatz_anlegen ($tabelle, $userid, $tabelleanlegen=1){
// legt einen Datensatz in die Virtuelle Tabelle
$userid = intval($userid);
if (intval($tabelle) > 0):
$vtid = intval($tabelle);
else:
$vtid = virtabelle_holen($tabelle, $tabelleanlegen);
endif;
if ($userid < 1 || $vtid < 1 )
return -1;
$sql = "insert into virdatensatz (start, userid, siteid, vtid) values (".time().", $userid, 0, $vtid)";
$ret = sql_query($sql); // ruft mysql_query auf, liefert bei INSERT gleich auch die mysql_insert_id
if ($ret>0):
return $ret; // neue id
else:
return -2;
endif;
}
function virdatensatz_holen ($tabelle, $feld="", $datenid=0, $counted=0, $sql_option="", $wherefelder=array(), $limit_start=0, $limit_ende=0)
{
// holt die datensätze samt felder und gibt einen hash zurück, einer virtabelle
// wenn feld angegeben ist kann man nur bestimmte felder holen, mehrere Felder in einem array
// wenn datenid > 0 , wird nur dieser Datensatz mit der datenid geholt
// wenn datenid ein ARRAY ist dann wird die 0 wie eine id betrachtet also id = 0 etc.
// if counted > 0 , dann wird der array als normaler und nicht als hash zurück gegeben, also wird die vid als id in den hashbestandteil eingesetz, wie normales datensatz_array_holen // beste einstellung
// wherefelder ist ein array( array("name"=>$name, "inhalt"=>$inhalt)), also hash in vektor
$vtid = virtabelle_holen($tabelle);
if ($vtid < 1)
return array();
$sql = "select b.name, b.inhalt, b.vid from virvar b ";
$sql .= " where b.siteid = 0 and b.art = $vtid ";
$sqlfelder = "";
// die gewünschten select felder
$feld = array_bauen($feld); // stellt sicher, dass das erg ein Array ist
$feld_anzahl = count($feld);
if ($feld_anzahl > 0):
$s = "";
for ($a=0;$a<$feld_anzahl;$a++):
$feld[$a] = trim($feld[$a]);
if ($feld[$a] != "")
$s .= " b.name = '" . $feld[$a] . "' or";
endfor;
if ($s != ""):
$sqlfelder = " and (" . substr($s, 0, -3) . ")";
endif;
endif;
if (intval($datenid) > 0 || (is_array($datenid) && count($datenid) > 0)):
// vtid ist hier nur sicherheit, dass auch die richtige virTabelle ausgewählt wurde, genauso auch die siteid
$datenid = array_bauen($datenid); // prüft ob array ist, sonst macht er eines draus
$sql .= " and ( ";
for ($a=0;$a<count($datenid);$a++):
$sql .= " b.vid = " . intval($datenid[$a]) . " or ";
endfor;
$sql = substr($sql, 0, -4) . " ) ";
$sql .= $sqlfelder;
else:
$wherefelder = array_bauen($wherefelder);
$anzahl = count($wherefelder);
if ($anzahl > 0):
$sql .= " and ( ";
for ($a=0;$a<$anzahl;$a++):
$sql .= "(b.name = '" . addslashes($wherefelder[$a][name]) . "' and b.inhalt = '" . addslashes($wherefelder[$a][inhalt]) . "')";
$sql .= " or ";
endfor;
$sql = substr($sql, 0, -4) . " ) ";
endif;
$sql .= $sqlfelder;
$sql .= " " . $sql_option; // suchanweisung bsp: and ((b.name = 'spalte1' and b.inhalt = 'inhalt1') or (b.name='spalte2' and b.inhalt='inhalt2') )
//$sql .= " , virdatensatz a where a.vtid = $vtid and b.vid = a.id and a.siteid = 0 and b.siteid = 0";
// nun haben wir die select anweisung um die virdatensätze zu erhalten, jetzt muessen wir noch die sqlfelder holen
if ($anzahl > 0):
// wherefelder vorhanden und muessen zuerst ausgewertet werden
$daten = datensatz_holen_array($sql); // macht mysql_query und mysql_fetch_array
$anzahl = count($daten);
$datenids = array();
if ($anzahl > 0):
for ($a=0;$a<$anzahl;$a++):
$datenids[] = $daten[$a][vid];
endfor;
endif;
if (count($datenids)>0):
return virdatensatz_holen($tabelle, $feld, $datenids, $counted, $sql_option);
else:
return array();
endif;
endif;
endif;
$daten = datensatz_holen_array($sql); // mysql_query und mysql_fetch_array
$anzahl = count($daten);
$datensatz = array();
if ($anzahl > 0):
for ($a=0;$a<$anzahl;$a++):
$key = $daten[$a][vid];
$key2 = $daten[$a][name];
$datensatz[$key][$key2] = $daten[$a][inhalt];
$datensatz[$key][id] = $key;
endfor;
if ($counted > 0):
$daten = array();
while (list($key, $wert) = each ($datensatz)){
$daten[] = $wert;
}
endif;
endif;
if ($counted > 0):
return $daten;
else:
return $datensatz;
endif;
}
function virdatensatz_komplett_aendern ($tabelle, $userid, $virdatensatzid, $werte)
{
// aendert die übergebenen Werte eines virdatensatzes
if (intval($tabelle) > 0):
$vtid = intval($tabelle);
else:
$vtid = virtabelle_holen($tabelle);
endif;
if ($userid < 1 || $vtid < 1 )
return -1;
$werte = array_bauen($werte); // prüft ob wert ein array ist, sonst macht es eines
for ($a=0;$a<count($werte);$a++):
function_aufrufen("virvar_register", $werte[$a][name], $vtid, $virdatensatzid, $userid, $werte[$a][inhalt]);
endfor;
return 1;
}
function virdatensatz_komplett_anlegen ($tabelle, $userid, $werte, $tabelleanlegen=1) {
// legt einen virdatensatz komplett mit seinen Feldern an.
// werte repräsentiert die einzelenen Spalten der Tabelle
// werte muessen in einem spezielle array vorliegen
// werte[][name] = name der var (spalte); werte[][inhalt] = inhalt der var (inhalt)
$vtid = virtabelle_holen($tabelle, $tabelleanlegen);
if ($vtid < 1 || $userid < 1)
return -1;
$virdatensatzid = virdatensatz_anlegen($vtid, $userid);
if ($virdatensatzid > 0):
virdatensatz_komplett_aendern($tabelle, $userid, $virdatensatzid, $werte);
endif;
return $virdatensatzid;
}
function virdatensatz_loeschen ($tabelle, $catid){
// löscht einen Datensatz einer virtuellen tabelle
// und löscht auch alle virvar dazu
$catid = intval($catid);
if (intval($tabelle) > 0):
$vtid = intval($tabelle);
else:
$vtid = virtabelle_holen($tabelle);
endif;
if ($catid < 1 || $vtid < 1)
return -1;
$sql = "delete from virdatensatz where vtid = $vtid and id = $catid and siteid = 0";
if (sql_query($sql) && sql_affected_rows()>0): // mysql_query && mysql_affected_row
virvar_all_delete($vtid, $catid);
return 1;
endif;
return 0;
}
function virvar_register ($var, $tabelle, $id, $userid, $wert = "", $sprache=0)
{
// legt eine var an, egal ob array oder string
// fuer die tabelle, wobei die id der identifier für den vid ist , also der bezieher zur anderen tabelle
// wenn wert nicht leer , dann wird der wert aus der variable wert genommen
$var = trim($var);
$tabelle = trim($tabelle);
$id = intval($id);
$sprache = intval($sprache);
$userid = intval($userid);
if ($var == "" || $id == 0 || $userid == 0 || $tabelle == "")
return 0;
$art = virtabelle_holen($tabelle, 1);
if ($art == 0)
return 0;
virvar_delete($var, $tabelle, $id, 1);
$var = addslashes($var);
$wert = array_bauen($wert);
for ($a=0;$a<count($wert);$a++):
$werte = addslashes($wert[$a]);
if ($werte != ""):
$sql = "insert into virvar";
$sql .= " (vid, name, inhalt, start, userid, art, siteid, reihe, sprache) values";
$sql .= " ($id, '$var', '$werte', ".time().", $userid, $art, ";
$sql .= "0, $a, $sprache)";
sql_query($sql);
endif;
endfor;
return 1;
}
function virvar_delete ($var, $tabelle, $id, $dont_unset=0, $sprache=0)
{
// loescht eine var
$var = trim ($var);
$tabelle = trim($tabelle);
$id = intval($id);
$sprache = intval($sprache);
if ($var == "" || $id == 0 || $tabelle == "")
return 0;
$var = addslashes($var);
$art = virtabelle_holen($tabelle, 1);
if ($art == 0)
return 0;
$sql = "delete from virvar";
$sql .= " where name = '$var' and vid = $id and art = $art";
$sql .= " and sprache = $sprache and siteid = 0";
sql_query($sql);
if ($dont_unset==0):
global $$var;
unset ($$var);
endif;
}
function virvar_unregister($var, $tabelle, $id, $readonly=0, $nur_ausgeben=0, $sprache=0)
{
// readonly = 1 ; loescht die Variable aus der var - tabelle
// readonly = 0 ; erhaehlt die Variable in der var - tabelle
// loecht bei nicht vorhanden, die variable
// tabelle darf nur den anfang enthalten, also BSP: content, anstatt contentvar !!
$var = trim($var);
$tabelle = trim($tabelle);
$id = intval($id);
if ($var=="" || $id == 0 || $tabelle == "")
return "";
$var = addslashes($var);
$art = virtabelle_holen($tabelle, 1);
if ($art == 0)
return 0;
$sprache = intval($sprache);
$sql = "select inhalt from virvar";
$sql .= " where name = '$var' and vid = $id and art = $art";
$sql .= " and sprache = $sprache and (";
$sql .= "siteid = 0";
$fremde_hosts = $System->holeHosts ();
for ($a=0;$a<count($fremde_hosts);$a++):
$sql .= " OR siteid = " . $fremde_hosts[$a];
endfor;
$sql .= ")";
$sql .= " order by reihe";
$virvar = datensatz_holen_array($sql);
$anzahl = count($virvar);
if ($nur_ausgeben == 0)
global $$var;
switch ($anzahl) {
case 0:
if ($nur_ausgeben == 1):
return "";
else:
return 0;
endif;
break;
case 1:
// variable sol nach dem lesen geloescht werden
if ($readonly == 0)
virvar_delete($var, $tabelle, $id, 1, $sprache);
$$var = stripslashes($virvar[0][inhalt]);
if ($nur_ausgeben == 0):
return 1;
else:
return $$var;
endif;
break;
default:
$temp = array();
for ($a=0;$a<$anzahl;$a++):
$temp[] = stripslashes($virvar[$a][inhalt]);
endfor;
if ($readonly == 0)
virvar_delete($var, $tabelle, $id, 1, $sprache);
if ($nur_ausgeben == 0):
$$var = $temp;
return 1;
else:
return $temp;
endif;
}// ende switch
}
// hilfsfunktion
function array_bauen ($wert, $bereinigt=1)
{
// wenn bereinigt = 1, wird nur nicht leere Werte übertragen
// konstruiert einen Array oder gibt den Array zurück
if (is_array($wert))
return $wert;
$werte = array();
if (trim($wert) != ""):
$werte[] = $wert;
elseif ($bereinigt == 0):
$werte[] = $wert;
endif;
return $werte;
}
Code
Um eine Variable zu belegen
$virdatensatzid = virdatensatz_anlegen ("meinVirTabelle", $userid);
virvar_register ("meineVar", "meineVirTabelle", $virdatensatzid, $userid, "meinWert");
echo virvar_unregister", "meineVar", "meineVirTabelle", $virdatensatzid, 1, 1);
Fazit
Sollen mit den Daten komplexe Datenbank-Operationen gemacht werden, ist die Nutzung von virtuellen Tabellen oft zu aufwendig und komplex und widerspricht dann dem Ansatz der Effizienz. Für reine Sicherung von Daten, welche nur ausgelesen und ab und an geändert werden sollen, ist der Nutzen sehr hoch. Gerade bei der Entwicklung. Wartbarkeit, bzw Operationen direkt über die Datenbank an den Daten sind sehr aufwendig und mühselig. Aber dafür könnte man auch ein Skript schreiben.
Saso Nikolov